Нормализация — это формальный метод анализа отношений на основе их первичного ключа (или потенциальных ключей, как в случае НФБК) и существующих функциональных зависимостей. Он включает ряд правил, которые могут использоваться для проверки отдельных отношений таким образом, чтобы вся база данных могла быть нормализована до желаемой степени нормализации. Если некоторое требование не удовлетворяется, то нарушающее данное требование отношение должно быть декомпозировано на отношения, каждое из которых (в отдельности) удовлетворяет всем требованиям нормализации.
Зачастую нормализация осуществляется в несколько последовательно выполняющихся этапов, каждый из которых соответствует некоторой нормальной форме, обладающей известными свойствами. В ходе нормализации формат отношений становится все более строгим и менее уязвимым по отношению к аномалиям обновления. При работе с реляционной моделью данных важно понимать, что только удовлетворение требований первой нормальной формы (1НФ) обязательно для создания отношений приемлемого качества. Все остальные формы могут использоваться по желанию проектировщиков. Однако, для того чтобы избежать аномалий обновления, нормализацию рекомендуется выполнять как минимум до ЗНФ.
На рисунке 6 показана схема процесса нормализации и продемонстрирована взаимосвязь между разными нормальными формами. Видно, что одни 1НФ-отношения могут находиться во 2НФ, другие 2НФ-отношения — в ЗНФ и т.д.
Ненормализованная форма (ННФ) – таблица, содержащая одну или несколько повторяющихся групп данных.
Первая нормальная форма (1НФ) – отношение, в котором на пересечении каждой строки и каждого столбца содержится только одно значение.
Процесс нормализации начинается с преобразования данных из формата источника (например, из формата стандартной формы ввода данных) в формат таблицы со строками и столбцами. На исходном этапе таблица находится в ненормализованной форме (ННФ) и часто называется ненормализованной таблицей. Для преобразования ненормализованной таблицы в первую нормальную форму (1НФ) в исходной таблице следует найти и устранить все повторяющиеся группы данных. Повторяющейся группой называется группа, состоящая из одного и более атрибутов таблицы, в которой возможно наличие нескольких значений для единственного значения ключевого атрибута таблицы. Существует два подхода исключения повторяющихся групп из ненормализованных таблиц.
В первом подходе повторяющиеся группы устраняются путем ввода соответствующих данных в пустые столбцы строк с повторяющимися данными. Иначе говоря, пустые места при этом заполняются дубликатами неповторяющихся данных. Этот подход часто называют "выравниванием" ("flattening") таблицы. Полученная в результате этих действий таблица, которая теперь будет называться отношением, содержит атомарные (или единственные) значения на пересечении каждой строки с каждым столбцом, а потому находится в первой нормальной форме. В результате такого подхода в полученное отношение вносится некоторая избыточность данных, которая в ходе дальнейшей нормализации будет устранена.
первом подходе повторяющиеся группы устраняются путем ввода соответствующих данных в пустые столбцы строк с повторяющимися данными. Иначе говоря, пустые места при этом заполняются дубликатами неповторяющихся данных. Этот подход часто называют "выравниванием" ("flattening") таблицы. Полученная в результате этих действий таблица, которая теперь будет называться отношением, содержит атомарные (или единственные) значения на пересечении каждой строки с каждым столбцом, а потому находится в первой нормальной форме. В результате такого подхода в полученное отношение вносится некоторая избыточность данных, которая в ходе дальнейшей нормализации будет устранена.
Во втором подходе один атрибут или группа атрибутов назначаются ключом ненормализованной таблицы, а затем повторяющиеся группы изымаются и помещаются в отдельные отношения вместе с копиями ключа исходной таблицы. Далее в новых отношениях устанавливаются первичные ключи. Иногда ненормализованные отношения могут содержать одну или несколько повторяющихся групп внутри повторяющихся групп первого порядка. В таких случаях данный прием применяется до тех пор, пока повторяющихся групп совсем не останется. Полученный набор отношений будет находиться в первой нормальной форме только тогда, когда ни в одном из них не будет повторяющихся групп атрибутов.
Хотя оба этих подхода одинаково корректны, следует отметить, что при использовании второго подхода полученные отношения находятся как минимум в 1НФ и обладают меньшей избыточностью данных. При выборе первого подхода выровненное 1НФ-отношение декомпозируется в ходе дальнейшей нормализации на те же отношения, которые могли бы быть получены с помощью второго подхода.
Предисловие
Нормализация отношений (таблиц) — одна из основополагающих частей теории реляционных баз данных. Нормализация имеет своей целью избавиться от избыточности в отношениях и модифицировать их структуру таким образом, чтобы процесс работы с ними не был обременён различными посторонними сложностями. При игнорировании такого подхода эффективность проектирования стремительно снижается, что вкупе с прочими подобными вольностями может привести к критическим последствиям.
Любому специалисту, по роду своей деятельности так или иначе связанному с проектированием реляционных баз данных, полезно понимать и уметь осуществить нормализацию отношений. И этим постом хотелось бы начать небольшую серию публикаций, посвящённых нормальным формам, имеющую целью дать тем читателям Хабрахабра, которые по различным обстоятельствам ещё не освоили эту тему, возможность легко заполнить этот пробел в знаниях.
Статья не имеет своей целью подробное и точное изложение принципов нормализациии, поскольку это, очевидно, невозможно в рамках блога в силу больших объёмов информации, необходимых для публикации при таком подходе. Кроме этого, для такой цели существует большое количество литературы, написанной прекрасными специалистами. Моя же задача, как я считаю, заключается в том, чтобы популярно продемонстрировать и объяснить основные принципы.
Используемые термины
Атрибут — свойство некоторой сущности. Часто называется полем таблицы.
Домен атрибута — множество допустимых значений, которые может принимать атрибут.
Кортеж — конечное множество взаимосвязанных допустимых значений атрибутов, которые вместе описывают некоторую сущность (строка таблицы).
Отношение — конечное множество кортежей (таблица).
Схема отношения — конечное множество атрибутов, определяющих некоторую сущность. Иными словами, это структура таблицы, состоящей из конкретного набора полей.
Проекция — отношение, полученное из заданного путём удаления и (или) перестановки некоторых атрибутов.
Функциональная зависимость между атрибутами (множествами атрибутов) X и Y означает, что для любого допустимого набора кортежей в данном отношении: если два кортежа совпадают по значению X, то они совпадают по значению Y. Например, если значение атрибута «Название компании» — Canonical Ltd, то значением атрибута «Штаб-квартира» в таком кортеже всегда будет Millbank Tower, London, United Kingdom. Обозначение:
Первая нормальная форма
Отношение находится в первой нормальной форме (сокращённо 1НФ), если все его атрибуты атомарны, то есть если ни один из его атрибутов нельзя разделить на более простые атрибуты, которые соответствуют каким-то другим свойствам описываемой сущности.
Будем называть исходное отношение основным, а значение неатомарного атрибута — подчинённым.
Для того, чтобы нормализовать исходное отношение, атрибуты которого неатомарны, необходимо объединить схемы основного и подчинённого отношений. Кроме того, если, например, таблица, соответствующая ненормализованному отношению уже содержится в БД и заполнена информацией, задача усложняется тем, что значение неатомарного атрибута может в свою очередь содержать несколько кортежей.
Следует пояснить сказанное на примере. Рассмотрим отношение, имеющее атрибуты «Код сотрудника», «ФИО», «Должность», «Проекты». Очевидно, что один сотрудник может работать над несколькими проектами. Предположим, что проект описывается идентификатором, названием и датой сдачи.
| Код сотрудника | ФИО | Должность | Проекты |
| 1 | Иванов Иван Иванович | Программист | ID: 123; Название: Система управления паровым котлом; Дата сдачи: 30.09.2011 ID: 231; Название: ПС для контроля и оповещения о превышениях ПДК различных газов в помещении; Дата сдачи: 30.11.2011 ID: 321; Название: Модуль распознавания лиц для защитной системы; Дата сдачи: 01.12.2011 |
Легко заметить, что не все атрибуты этого отношения атомарны (неделимы). В частности, атрибут «Проекты» можно разделить на три более простых атрибута: «Код проекта», «Название», «Дата сдачи», а значение этого атрибута для сотрудника Иван Иванович Иванов содержит несколько кортежей — информацию о трёх проектах.
Примечание: с некоторой точки зрения атрибут «ФИО» можно также считать неатомарным и в таком случае его также следует разделить на более простые, как «Фамилия», «Имя», «Отчество».
Теперь настало время рассмотреть алгоритм нормализации отношения до 1НФ.
- Создать новое отношение, схема которого будет получена путём слияния основной и подчинённой схем исходного отношения в одну.
- Для каждого кортежа исходного отношения включить в новое столько строк, сколько кортежей содержится в подчинённом отношении этого кортежа.
- Заполнить значения атрибутов нового отношения, соответствующих атрибутам подчинённого отношения.
- Заполнить строки нового отношения значениями атомарных атрибутов исходного.
Применим этот алгоритм к приведённому выше отношению. Схема нового отношения будет состоять из 6 атрибутов: «Код сотрудника», «ФИО», «Должность», «Код проекта», «Название», «Дата сдачи». Для одного единственного кортежа заданного отношения, добавим в новое три строки, по одной для каждого проекта (по количеству кортежей в подчинённом отношении). Теперь можно заполнить значения разделённых атрибутов кортежами из подчинённого отношения. Затем перенесём в каждую из этих строк значения атомарных атрибутов: «Код сотрудника», «ФИО», «Должность» (как Вы уже догадались, все три строки будут содержать одинаковые значения этих атрибутов).
Результат будет выглядеть так:
| Код сотрудника | ФИО | Должность | Код проекта | Название | Дата сдачи |
| 1 | Иванов Иван Иванович | Программист | 123 | Система управления паровым котлом | 30.09.2011 |
| 1 | Иванов Иван Иванович | Программист | 231 | ПС для контроля и оповещения о превышениях ПДК различных газов в помещении | 30.11.2011 |
| 1 | Иванов Иван Иванович | Программист | 321 | Модуль распознавания лиц для защитной системы | 01.12.2011 |
Вторая нормальная форма
Ясно, что отношение, находящееся в 1НФ, также может обладать избыточностью. Для её устранения предназначена вторая нормальная форма. Но прежде чем приступить к её описанию, сначала следует выявить недостатки первой.
Пусть исходное отношение содержит информацию о поставке некоторых товаров и их поставщиках.
| Код поставщика | Город | Статус города | Код товара | Количество |
| 1 | Москва | 20 | 1 | 300 |
| 1 | Москва | 20 | 2 | 400 |
| 1 | Москва | 20 | 3 | 100 |
| 2 | Ярославль | 10 | 4 | 200 |
| 3 | Ставрополь | 30 | 5 | 300 |
| 3 | Ставрополь | 30 | 6 | 400 |
| 4 | Псков | 15 | 7 | 100 |
Заранее известно, что в этом отношении содержатся следующие функциональные зависимости:
< <Код поставщика, Код товара>-> < Количество>,
<Код поставщика>-> <Город>,
<Код поставщика>-> <Статус>,
<Город>-> <Статус>>
Очевидно, что отношение обладает избыточностью: оно описывает две сущности — поставку и поставщика. В связи с этим возникают следующие аномалии:
- Аномалия вставки. В отношение нельзя добавить информацию о поставщике, который ещё не поставил ни одного товара.
- Аномалия удаления. Если от поставщика была только одна поставка, то при удалении информации о ней будет удалена и вся информация о поставщике.
- Аномалия обновления. Если необходимо изменить какую-либо информацию о поставщике (например, поставщик переехал в другой город), то придётся изменять значения атрибутов во всех записях о поставках от него.
Физический смысл избыточности исходного отношения заключается в том, что оно описывает не одну сущность, а две — поставку и поставщика.
Чтобы устранить эти аномалии, необходимо разбить исходное отношение на проекции:
- В первую следует включить первичный ключ и все неключевые атрибуты явно зависимые от него.
- В остальные проекции (в данном случае она одна) будут включены неключевые атрибуты, зависящие от первичного ключа неявно, вместе с той частью первичного ключа, от которой эти атрибуты зависят явно.
В итоге будут получены два отношения:
| Код поставщика | Код товара | Количество |
| 1 | 1 | 300 |
| 1 | 2 | 400 |
| 1 | 3 | 100 |
| 2 | 4 | 200 |
| 3 | 5 | 300 |
| 3 | 6 | 400 |
| 4 | 7 | 100 |
Первому отношению теперь соответствуют следующие функциональные зависимости:
<Код поставщика, Код товара>-><Количество>
| Код поставщика | Город | Статус города |
| 1 | Москва | 20 |
| 2 | Ярославль | 10 |
| 3 | Ставрополь | 30 |
| 4 | Псков | 15 |
Второму отношению соответствуют:
< <Код поставщика>-><Город>,
<Код поставщика>-><Статус>,
<Город>-><Статус>>
Такое разбиение устранило аномалии, описанные выше: можно добавить информацию о поставщике, который ещё не поставлял товар, удалить информацию о поставке без удаления информации о поставщике, а также легко обновить информацию в случае если поставщик переехал в другой город.
Теперь можно сформулировать определение второй нормальной формы, до которого, скорее всего, читатель уже смог догадаться самостоятельно: отношение находится во второй нормальной форме (сокращённо 2НФ) тогда и только тогда, когда оно находится в первой нормальной форме и каждый его неключевой атрибут неприводимо зависим от первичного ключа.
Рассмотренные ранее отношения можно демонстрировать не только в качестве объектных и связных отношений, но и как пример нормализованных отношений реляционной базы данных. Эти отношения получились не сразу. Сначала для решения задачи о хранении товаров на складах и магазинах должна была появиться, например, следующая таблица (Подразделение_товар):
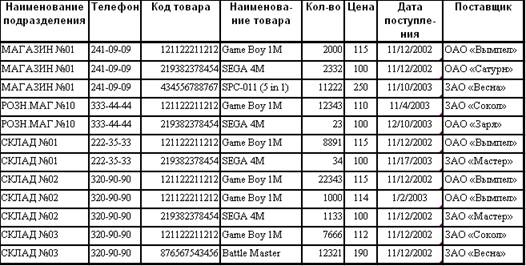
В общем-то, в этой таблице нет ничего необычного, но она могла бы содержать строк 100 или 100000. Такую таблицу можно было бы записать, например в Excel и вести учет товаров на складах и в магазинах, разложив перед собой документы движения товаров (накладные). При этом анализировать данные такой «базы данных» в Excel не очень трудно — там имеются хорошие средства, в том числе сводные таблицы. Обновление же данных представляет определенные проблемы (хотя и разрешимые).
Хотя следовало бы показать «полную невозможность» размещения данных так, как это сделано в таблице Подразделение_товар, отметим, что в Excel для работы с такой таблицей имеется аппарат форм, которые позволяют находить и изменять данные способом, во многом похожим на работу с базой данных. Автоматически созданная для этой таблицы форма представлена на рис. 14.4. Обратите внимание на наименования кнопок этой формы. Не говоря уже о том, что данные можно редактировать (после нахождения при помощи кнопок Назад, Далее), их можно удалять и добавлять. Но самой, конечно, полезной кнопкой является кнопка Критерии. Именно при помощи этой кнопки можно найти в довольно большой таблице данные, имея о них некоторые сведения.
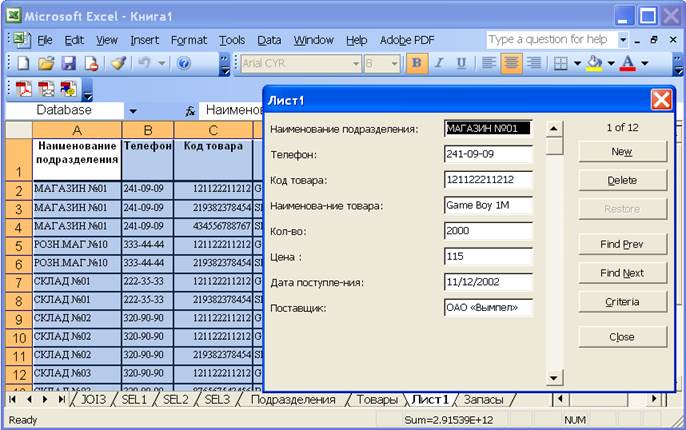
Автоматически созданная форма для таблицы Подразделение_товар
Конечно, небольшие несвязанные между собой таблицы можно сопровождать таким способом. Однако, видимо, не очень удобно заносить новые сведения о товарах, если придется несколько раз набирать на клавиатуре сведения о магазине, куда поступает товар, о поставщике товара и д.т. Если при этом будут совершаться ошибки, то может получиться так, что товар будет «помещен» в новый ошибочный магазин или связан с несуществующим поставщиком. Многие другие ошибки при обслуживании таких таблиц могут возникать из-за неуверенной работы пользователя в Excel.
Этот пример предваряет введение в понятие нормализации отношений в реляционной базе данных, которые должны удовлетворять двум основным требованиям:
· между атрибутами не должно быть нежелательных функциональных зависимостей;
· группировка атрибутов должна обеспечивать минимальное дублирование данных.
Для выполнения этих требований используется нормализация отношений — пошаговый обратимый процесс декомпозиции исходных отношений базы данных на более простые отношения. С процессом нормализации связаны нормальные формы, каждая из которых ограничивает типы допустимых функциональных зависимостей отношений.
Кодд выделил три нормальные формы[5] и предложил правила последовательного приведения отношений к нормализованному виду.
Отношение находится в первой нормальной форме, если все неключевые атрибуты функционально зависят от ключа. Для приведения к первой нормальной форме исходные данные (самая общая таблица с данными) разделяются на логически связанные таблицы, в большинстве из которых определяются первичные ключи. В такой совокупности таблиц не должно содержаться повторяющихся данных.
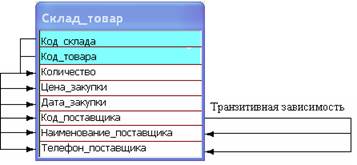
Рассмотрим, например, отношение Склад_товар (рис. 14.5), в котором сохраняются записи о складах и товарах поступающих на эти склады от некоторых поставщиков.

Структура отношения Склад_товар
Подразделение Склад_товар находится в первой нормальной форме, поскольку не содержит сложных (составных) атрибутов. Можно отметить, что в этом отношении имеет место дублирование данных о подразделении (у подразделения может быть не один телефон), о товаре (наименование, цена, поставщик) и т.д.
Рассмотрим зависимости атрибутов от первичного ключа, роль которого должны выполнять атрибуты Код_склада, Код_товара:
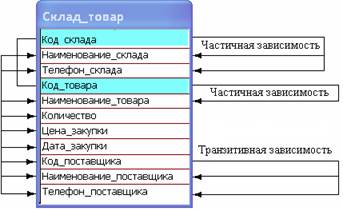
Зависимости атрибутов от первичного ключа
Отметим, что указанные связи, вообще-то, могут определяться бизнес-правилами и быть отличными от представленных здесь.
Теперь — о типах зависимостей. На рис. 14.6 представлены три типа связей: слева — полные функциональные зависимости атрибутов от составного ключа (это «полезные» зависимости), справа — частичные (атрибут зависит от части составного ключа) и транзитивные зависимости (неключевые атрибуты зависят от неключевого атрибута).
Хотя иногда частичные зависимости используются для повышения производительности, следует учитывать, что отношения с такими зависимостями имеют недостаток — содержат избыточные данные и приводят к различным аномалиям. Например, если для одного и того же склада вводятся различные товары с одним поставщиком, то приходится для каждой записи повторять не только код склада, код товара, количество, цену и дату (что, вообще-то, необходимо в любом случае), но — наименование и телефон склада, наименование поставщика. Представьте себе такую ситуацию: на склад «Четвертого первомайского проезда» (клад имеет два телефонных номера) поступил всего один товар от поставщика «Волгоградский завод им. Куйбышева» (поставщик имеет два телефона); даже если поступивший товар уже ранее записывался в эту таблицу (возможно, для других складов), вам необходимо будет ввести примерно следующие записи:
3003; склад Четвертого первомайского проезда; (095) 555-77-55; 112299993333; Мишка плюшевый, голубой, музыкальный; 300; 30.00 ; 20/08/2003; 4004; Волгоградский завод им. Куйбышева; (956) 777-88
3003; склад Четвертого первомайского проезда; (095) 555-77-78; 112299993333; Мишка плюшевый, голубой, музыкальный; 300; 30.00 ; 20/08/2003; 4004; Волгоградский завод им. Куйбышева; (956) 777-88
3003; склад Четвертого первомайского проезда; (095) 555-77-55; 112299993333; Мишка плюшевый, голубой, музыкальный; 300; 30.00 ; 20/08/2003; 4004; Волгоградский завод им. Куйбышева; (956) 777-86
3003; склад Четвертого первомайского проезда; (095) 555-77-78; 112299993333; Мишка плюшевый, голубой, музыкальный; 300; 30.00 ; 20/08/2003; 4004; Волгоградский завод им. Куйбышева; (956) 777-86
Здесь содержимое полей разделяется точкой с запятой (;). Поскольку склад и поставщик имеют по два телефонных номера, нам необходимо иметь запись в таблице для каждого телефона. Таким образом, мы для одной товарной позиции должны вводить и хранить четыре записи.
Для устранения недостатков отношения, находящегося в первой нормальной форме, необходимо привести отношение, по крайней мере, к третьей нормальной форме. При этом мы должны избавиться от связей, расположенных в левой части рис. 14.6.
Отношение находится во второй нормальной форме, если оно находится в первой нормальной форме и каждый неключевой атрибут функционально полно зависит от составного ключа. Таким образом, для приведения отношения к этой форме нужно поместить в отдельную таблицу данные, которые только частично зависят от первичного ключа. По Кодду следует построить проекцию[6] без атрибутов, которые находятся в частичной функциональной зависимости от составного ключа (рис. 14.7), а затем построить проекцию(и) на часть составного ключа и атрибуты, зависящие от этой части (рис.14.8).
Проекция без атрибутов, которые находятся в частичной функциональной зависимости от составного ключа
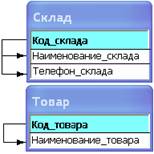
Проекции на часть составного ключа и атрибуты, зависящие от этой части ключа
В отношениях, представленных на рис. 14.8, определены первичные ключи, соответствующие отдельным элементам составного ключа исходного отношения.
Отношение находится в третьей нормальной форме, если оно находится во второй нормальной форме и в нем отсутствуют транзитивные зависимости неключевых атрибутов от ключа. Целью приведения отношения к третьей нормальной форме является удаление из него данных, не зависящих от первичного ключа (для устранения аномалий, связанных с транзитивными зависимостями).
В отношении Склад_товар имеются транзитивные зависимости (рис. 14.6). Для приведения отношения к третьей нормальной форме следует создать еще одно отношение, в которое войдут все неключевые атрибуты, связанные транзитивной зависимостью (рис. 14.9). При этом неключевой атрибут, от которого зависят остальные неключевые атрибуты, должен стать первичным ключом в новом отношении и внешним ключом в оригинальном отношении. Зависимые атрибуты из оригинального отношения удаляются (рис. 14.10).

Отношение, в которое вошли неключевые атрибуты, связанные транзитивной зависимостью
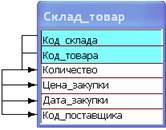 Рис. 14.10
Рис. 14.10
Зависимые атрибуты удаляются из оригинального отношения
Остается установить связи между полученными отношениями[7], как показано на рис. 14.11.

Остается установить связи между полученными отношениями
В рамках этой книги мы не будем далее углубляться в теоретические «лабиринты» реляционных баз данных, поскольку на полках книжных магазинов можно найти достаточно специализированной литературы по базам данных. К тому же на практике часто удается сразу сформировать базу из нескольких отношений, отвечающих третьей нормальной форме. С другой стороны, работая с таким языком, как SQL, иногда приходится думать о том, что отношения в базе данных излишне нормализованы, что влияет на производительность СУБД.
Visual Basic (как и многие Visual-системы программирования) не является СУБД в том смысле, что его язык не содержит команд и функций обработки записей файлов данных. Однако Visual Basic для управления базами данных использует процессор баз данных (database engine), т.е. систему «отвечающую» за хранение и выборку данных[8]. Процессор баз данных для Visual Basic, называется Microsoft Jet и представляет собой систему, используемую несколькими программными продуктами фирмы Microsoft. Visual-системы программирования позволяют использовать при работе с базами данных язык SQL. Получается очень простая схема работы с базами данных: Visual Basic обеспечивает интерфейс, а SQL — работу с данными. Если же учесть, что Visual Basic — самая легкая в освоении система программирования, то можно сделать вывод, что самый простой способ быстро построить небольшое приложение для работы с базой данных — сделать это при помощи именно Visual Basic.
Дата добавления: 2015-08-14 ; просмотров: 1250 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ